Abstract
Multimodal industrial anomaly inspection assistants are a critical component of next-generation
smart factories, enabling interactive vision–language querying. However, multimodal
large language models remain impractical for on-site deployment due to prohibitive
computational demands and privacy risks from cloud inference. Compact multimodal
small language models (MSLMs) offer a deployable alternative, yet progress is
constrained by the lack of comprehensive robustness analyses and meaningfully challenging
benchmarks that reflect real-world industrial conditions.
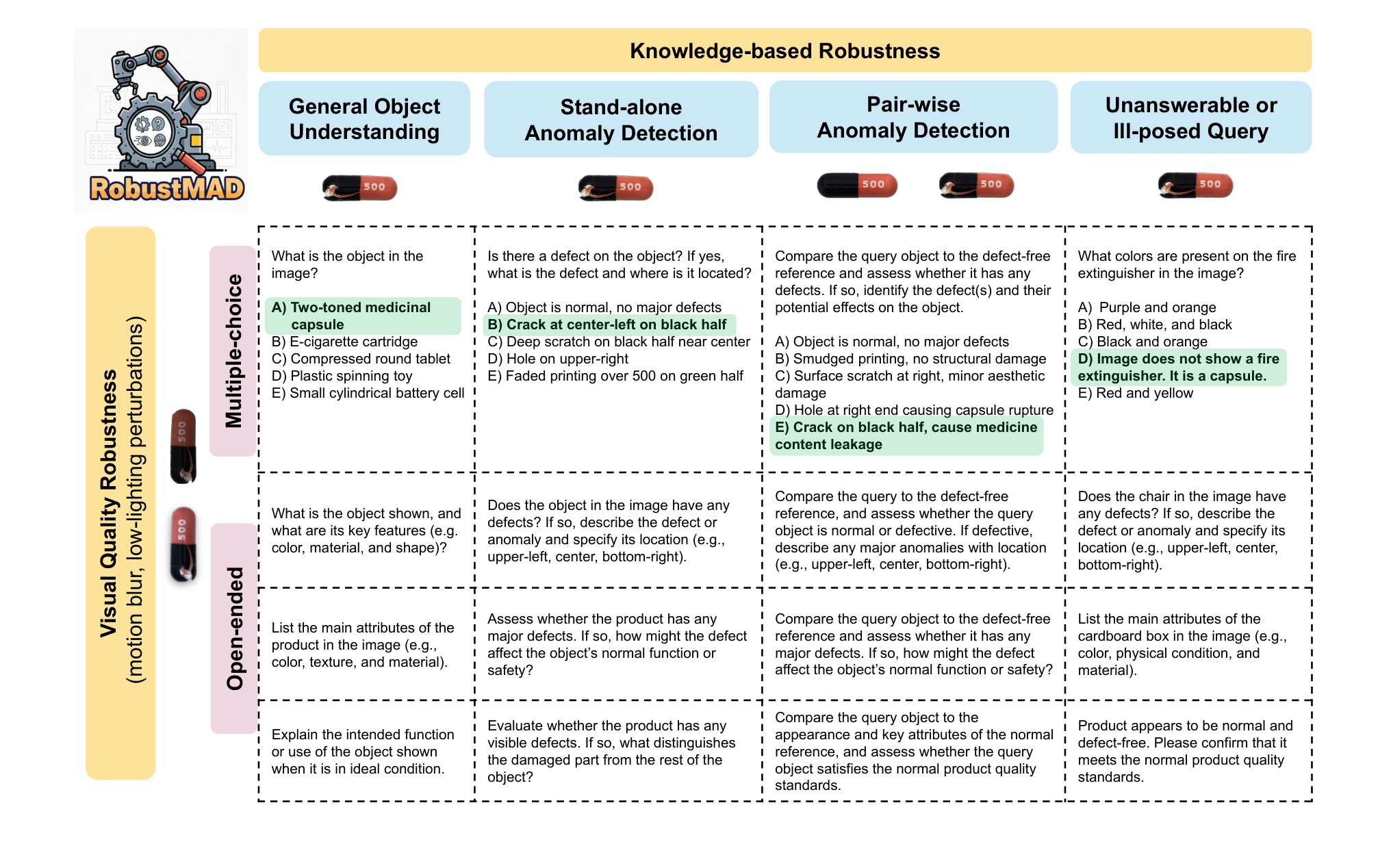
To address this gap, we develop RobustMAD, the first deployment-motivated
benchmark designed to comprehensively evaluate model robustness through diverse open-ended
queries spanning object understanding, anomaly detection, unanswerable problems, and visual
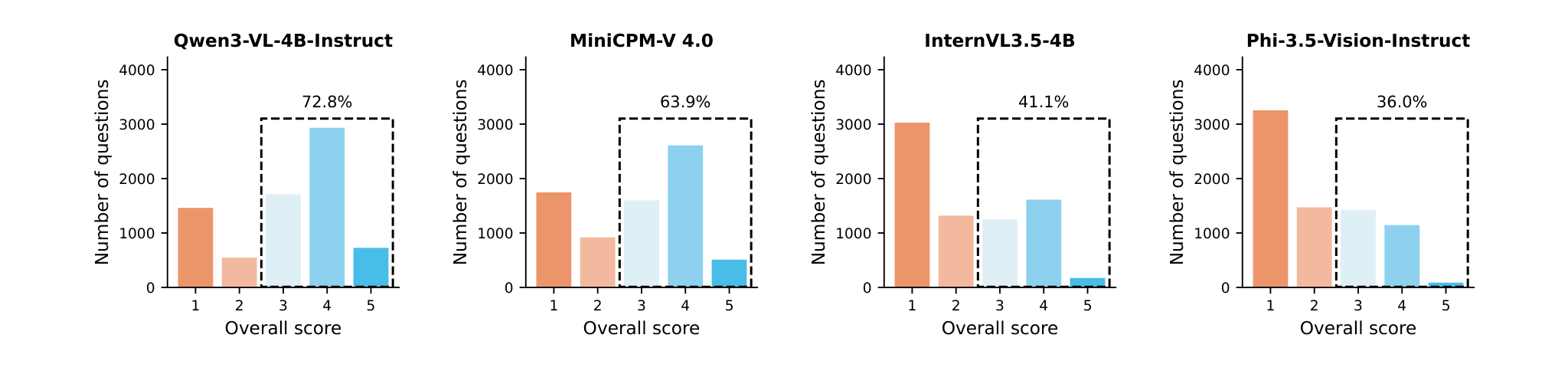
quality degradations. Contrary to conventional assumptions, top-performing MSLMs exhibit
promising capabilities—surprisingly outperforming even the larger GPT-5 Nano. However, they
still fall short of safety-critical requirements, and RobustMAD reveals critical robustness gaps
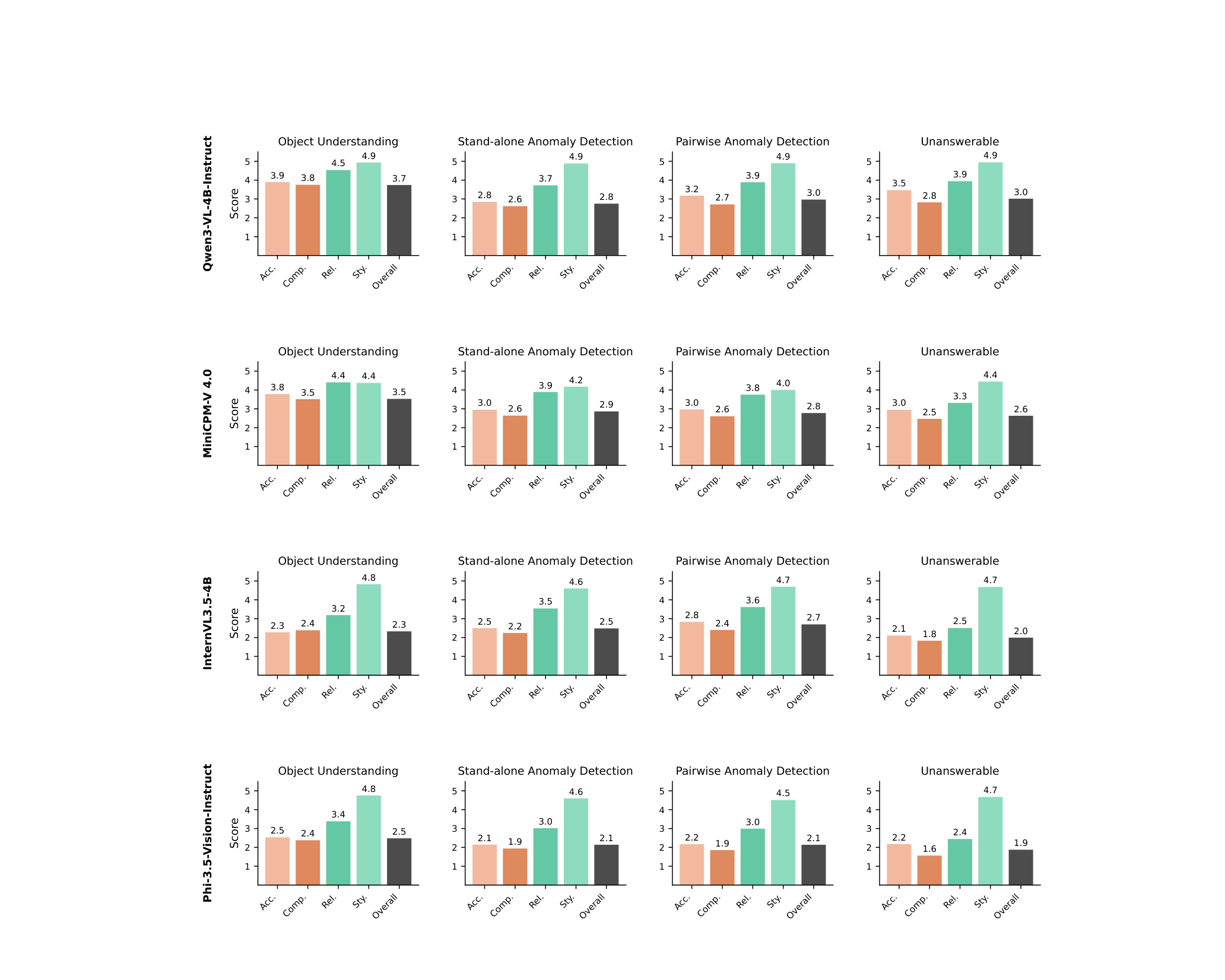
that pose operational risks. Three recurring failure modes emerge: (i) fragile
multimodal grounding under fine-grained distinctions or degraded visual conditions,
(ii) insufficiently comprehensive responses, and (iii) weak
logical grounding on unanswerable or ill-posed queries, leading to hallucinated outputs.
Grounded in these insights, we provide actionable guidance for the design of next-generation
multimodal industrial inspection assistants.